直观上,随机变量为一种特殊的实函数,其值不大于某数的状况都是事件。所以一个函数是不是随机变量也跟“怎样的子集合算事件”有密不可分的关系。
如果随机变量  的取值是有限的或者是可数无穷尽的值:
的取值是有限的或者是可数无穷尽的值:

则称 为离散随机变量。如果 的取值遍布一区间甚至是整个数线:( )
)
![{\displaystyle X(S)=[a,\,b]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/df17530074a67b7e46f3c915cff7829ece9717b2)
则称 为连续随机变量。
如果取  为所有实开区间所构成的集合:
为所有实开区间所构成的集合:
![{\displaystyle {\mathcal {I}}={\bigg \{}A\in {\mathcal {P}}(\mathbb {R} )\,{\bigg |}\,(\exists a)(\exists b)\left[\,(a,\,b\in \mathbb {R} )\wedge (A=(a,\,b))\,\right]{\bigg \}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/5d0bd0ac0429611111bd22048ae71d327e7e57cb)
则可以把博雷尔代数  定义为包含 的最小Σ-代数:
定义为包含 的最小Σ-代数:

则根据阿基米德性质,对任意实数  ,
,![{\displaystyle (-\infty ,\,r]\in {\mathcal {B}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/4d9e2cefbdce60da2e8821bca1926e11247a0a8b) ,有以下的关系:
,有以下的关系:
![{\displaystyle (r,\,\infty )=\bigcup \left\{A\in {\mathcal {I}}\,{\bigg |}\,(\exists n\in \mathbb {N} )\left[A=(r,\,n)\right]\right\}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/0c02dadb05b9092a3ca3b9807618361f38872b6a)
![{\displaystyle (-\infty ,\,r]=\mathbb {R} -(r,\,\infty )}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a6bc762ee629f43a023a45a8cd254d44b3e91768)
反之,也可以用类似的方法,由任意的 ![{\displaystyle (-\infty ,\,r]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/960a6fafe2d4ddb72b638f794620827e8d069d6c) ,透过并集和补集组合出
,透过并集和补集组合出  :
:
![{\displaystyle (-\infty ,\,b)=\bigcup \left\{A\in {\mathcal {P}}(\mathbb {R} )\,{\bigg |}\,(\exists n\in \mathbb {N} )\left[A=(-\infty ,\,b-{\frac {1}{n}}]\right]\right\}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/57b540d9f91cffaf32042c5bbd4b2012abb66485)
![{\displaystyle (a,\,b)=\left(\mathbb {R} -(-\infty ,\,a]\right)\cup (-\infty ,b)}](https://wikimedia.org/api/rest_v1/media/math/render/svg/65909ed0997d08904c413d8e0fbbd9827ceee25b)
这样的话,任意的 都有 ,等价于对任意的 都有
,等价于对任意的 都有  ,这样根据可测函数性质的定理(2),上小节定义的 ,就是一个
,这样根据可测函数性质的定理(2),上小节定义的 ,就是一个  - 可测函数,换句话说,随机变量是可测函数的一种特例。
- 可测函数,换句话说,随机变量是可测函数的一种特例。
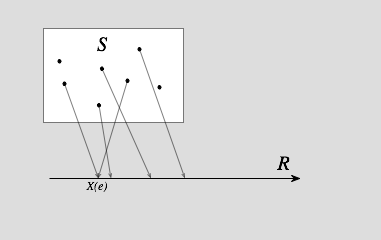 实数坐标轴上的随机变量示意图
实数坐标轴上的随机变量示意图
随机掷两个骰子,整个样本空间由36个元素组成:

然后可以简单地把  的任意子集合都视为事件,换句话说,把事件族 取成 的幂集:
的任意子集合都视为事件,换句话说,把事件族 取成 的幂集:

这样的话,可以构造出许多定义在 上的随机变量,比如 可以定义为“两个骰子的点数和”;者  可以定义为“两个骰子的点数差”:
可以定义为“两个骰子的点数差”:


因为“两个骰子的点数和不大于  ”和“两个骰子的点数差不大于 ”的样本点所构成的集合,都是 的子集合,所以 和 都是(在 的意义下)定义在 上的随机变量,而且它们都是离散随机变量。
”和“两个骰子的点数差不大于 ”的样本点所构成的集合,都是 的子集合,所以 和 都是(在 的意义下)定义在 上的随机变量,而且它们都是离散随机变量。
随机试验结果的量的表示。例如掷一颗骰子出现的点数,电话交换台在一定时间内收到的调用次数,随机抽查的一个人的身高,悬浮在液体中的微粒沿某一方向的位移,等等,都是随机变量的实例。
一个随机试验的可能结果(称为基本事件)的全体组成一个基本空间 (见概率)。随机变量 是定义于 上的函数,即对每一基本事件
(见概率)。随机变量 是定义于 上的函数,即对每一基本事件 ,有一数值
,有一数值 与之对应。以掷一颗骰子的随机试验为例,它的所有可能结果,共6个,分别记作
与之对应。以掷一颗骰子的随机试验为例,它的所有可能结果,共6个,分别记作 ,
,  ,
,  ,
,  ,
,  ,
,  ,这时,
,这时, ,而出现的点数这个随机变量 ,就是 上的函数
,而出现的点数这个随机变量 ,就是 上的函数 ,
, 。又如设
。又如设 是要进行抽查的
是要进行抽查的 个人的全体,那么随意抽查其中一人的身高和体重,就构成两个随机变量 和 ,它们分别是 上的函数:
个人的全体,那么随意抽查其中一人的身高和体重,就构成两个随机变量 和 ,它们分别是 上的函数: “
“ 的身高”,
的身高”, “ 的体重”,
“ 的体重”, 。一般说来,一个随机变量所取的值可以是离散的(如掷一颗骰子的点数只取1到6的整数,电话台收到的调用次数只取非负整数),也可以充满一个数值区间,或整个实数轴(如液体中悬浮的微粒沿某一方向的位移)。
。一般说来,一个随机变量所取的值可以是离散的(如掷一颗骰子的点数只取1到6的整数,电话台收到的调用次数只取非负整数),也可以充满一个数值区间,或整个实数轴(如液体中悬浮的微粒沿某一方向的位移)。
在研究随机变量的性质时,确定和计算它取某个数值或落入某个数值区间内的概率是特别重要的。因此,随机变量取某个数值或落入某个数值区间这样的基本事件的集合,应当属于所考虑的事件域。根据这样的直观想法,利用概率论公理化的语言,取实数值的随机变量的数学定义可确切地表述如下:概率空间 上的随机变量 是定义于 上的实值可测函数,即对任意 , 为实数,且对任意实数
上的随机变量 是定义于 上的实值可测函数,即对任意 , 为实数,且对任意实数 ,使
,使 的一切
的一切 组成的 的子集
组成的 的子集 是事件,也即是
是事件,也即是 中的元素。事件 常简记作
中的元素。事件 常简记作 ,并称函数
,并称函数 ,
, ,为 的分布函数。
设 , 是概率空间 上的两个随机变量,如果除去一个零概率事件外, 与
,为 的分布函数。
设 , 是概率空间 上的两个随机变量,如果除去一个零概率事件外, 与 相同,则称
相同,则称 以概率1成立,也记作
以概率1成立,也记作 或 ,α.s.(α.s.意即几乎必然)。
或 ,α.s.(α.s.意即几乎必然)。
有些随机现象需要同时用多个随机变量来描述。例如对地面目标射击,弹着点的位置需要两个坐标才能确定,因此研究它要同时考虑两个随机变量,一般称同一概率空间 上的 个随机变量构成的 维向量 为 维随机向量。随机变量可以看作一维随机向量。称 元
为 维随机向量。随机变量可以看作一维随机向量。称 元 的函数为 的(联合)分布函数。又如果
的函数为 的(联合)分布函数。又如果 为二维随机向量,则称
为二维随机向量,则称 为复随机变量。
随机变量的独立性 独立性是概率论所独有的一个重要概念。设 是 个随机变量,如果对任何 个实数 都有 即它们的联合分布函数
为复随机变量。
随机变量的独立性 独立性是概率论所独有的一个重要概念。设 是 个随机变量,如果对任何 个实数 都有 即它们的联合分布函数 等于它们各自的分布函数
等于它们各自的分布函数 的乘积。则称 是独立的。这一定义可以直接推广到每一
的乘积。则称 是独立的。这一定义可以直接推广到每一 ( )是随机向量的情形。独立性的直观意义是: 中的任何一个取值的概率规律,并不随其中的其他随机变量取什么值而改变。在实际问题中通常用它来表征多个独立操作的随机试验结果或多种有独立来源的随机因素的概率特性,因此它对于概率统计的应用是十分重要的。
( )是随机向量的情形。独立性的直观意义是: 中的任何一个取值的概率规律,并不随其中的其他随机变量取什么值而改变。在实际问题中通常用它来表征多个独立操作的随机试验结果或多种有独立来源的随机因素的概率特性,因此它对于概率统计的应用是十分重要的。
从随机变量(或向量) 的独立性还可以推出:设 是 取值的空间中的任意波莱尔集, 。设 是独立的,则它们中的任意个都是独立的。但逆之即使其中任何
是 取值的空间中的任意波莱尔集, 。设 是独立的,则它们中的任意个都是独立的。但逆之即使其中任何 个是独立的,也不保证 是独立的。又如果
个是独立的,也不保证 是独立的。又如果 ,是 个连续函数或初等函数(或更一般的波莱尔可测函数),则从 的独立性可推出
,是 个连续函数或初等函数(或更一般的波莱尔可测函数),则从 的独立性可推出 也独立。如果随机变量(随机向量)序列
也独立。如果随机变量(随机向量)序列 中任何有限个都独立,则称之为独立随机变量(随机向量)序列。
关于随机变量的矩、特征函数、母函数及半不变量,分别见数学期望、方差、矩及概率分布。
中任何有限个都独立,则称之为独立随机变量(随机向量)序列。
关于随机变量的矩、特征函数、母函数及半不变量,分别见数学期望、方差、矩及概率分布。















