直觀上,隨機變量為一種特殊的實函數,其值不大於某數的狀況都是事件。所以一個函數是不是隨機變量也跟「怎樣的子集合算事件」有密不可分的關係。
如果隨機變量  的取值是有限的或者是可數無窮盡的值:
的取值是有限的或者是可數無窮盡的值:

則稱 為離散隨機變量。如果 的取值遍布一區間甚至是整個數線:( )
)
![{\displaystyle X(S)=[a,\,b]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/df17530074a67b7e46f3c915cff7829ece9717b2)
則稱 為連續隨機變量。
如果取  為所有實開區間所構成的集合:
為所有實開區間所構成的集合:
![{\displaystyle {\mathcal {I}}={\bigg \{}A\in {\mathcal {P}}(\mathbb {R} )\,{\bigg |}\,(\exists a)(\exists b)\left[\,(a,\,b\in \mathbb {R} )\wedge (A=(a,\,b))\,\right]{\bigg \}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/5d0bd0ac0429611111bd22048ae71d327e7e57cb)
則可以把博雷爾代數  定義為包含 的最小Σ-代數:
定義為包含 的最小Σ-代數:

則根據阿基米德性質,對任意實數  ,
,![{\displaystyle (-\infty ,\,r]\in {\mathcal {B}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/4d9e2cefbdce60da2e8821bca1926e11247a0a8b) ,有以下的關係:
,有以下的關係:
![{\displaystyle (r,\,\infty )=\bigcup \left\{A\in {\mathcal {I}}\,{\bigg |}\,(\exists n\in \mathbb {N} )\left[A=(r,\,n)\right]\right\}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/0c02dadb05b9092a3ca3b9807618361f38872b6a)
![{\displaystyle (-\infty ,\,r]=\mathbb {R} -(r,\,\infty )}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a6bc762ee629f43a023a45a8cd254d44b3e91768)
反之,也可以用類似的方法,由任意的 ![{\displaystyle (-\infty ,\,r]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/960a6fafe2d4ddb72b638f794620827e8d069d6c) ,透過併集和補集組合出
,透過併集和補集組合出  :
:
![{\displaystyle (-\infty ,\,b)=\bigcup \left\{A\in {\mathcal {P}}(\mathbb {R} )\,{\bigg |}\,(\exists n\in \mathbb {N} )\left[A=(-\infty ,\,b-{\frac {1}{n}}]\right]\right\}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/57b540d9f91cffaf32042c5bbd4b2012abb66485)
![{\displaystyle (a,\,b)=\left(\mathbb {R} -(-\infty ,\,a]\right)\cup (-\infty ,b)}](https://wikimedia.org/api/rest_v1/media/math/render/svg/65909ed0997d08904c413d8e0fbbd9827ceee25b)
這樣的話,任意的 都有 ,等價於對任意的 都有
,等價於對任意的 都有  ,這樣根據可測函數性質的定理(2),上小節定義的 ,就是一個
,這樣根據可測函數性質的定理(2),上小節定義的 ,就是一個  - 可測函數,換句話說,隨機變量是可測函數的一種特例。
- 可測函數,換句話說,隨機變量是可測函數的一種特例。
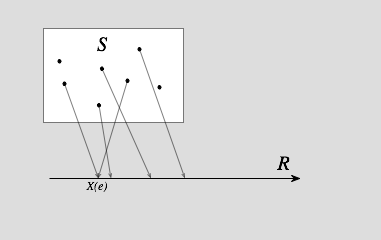 實數坐標軸上的隨機變量示意圖
實數坐標軸上的隨機變量示意圖
隨機擲兩個骰子,整個樣本空間由36個元素組成:

然後可以簡單地把  的任意子集合都視為事件,換句話說,把事件族 取成 的冪集:
的任意子集合都視為事件,換句話說,把事件族 取成 的冪集:

這樣的話,可以構造出許多定義在 上的隨機變量,比如 可以定義為「兩個骰子的點數和」;者  可以定義為「兩個骰子的點數差」:
可以定義為「兩個骰子的點數差」:


因為「兩個骰子的點數和不大於  」和「兩個骰子的點數差不大於 」的樣本點所構成的集合,都是 的子集合,所以 和 都是(在 的意義下)定義在 上的隨機變量,而且它們都是離散隨機變量。
」和「兩個骰子的點數差不大於 」的樣本點所構成的集合,都是 的子集合,所以 和 都是(在 的意義下)定義在 上的隨機變量,而且它們都是離散隨機變量。
隨機試驗結果的量的表示。例如擲一顆骰子出現的點數,電話交換台在一定時間內收到的呼叫次數,隨機抽查的一個人的身高,懸浮在液體中的微粒沿某一方向的位移,等等,都是隨機變量的實例。
一個隨機試驗的可能結果(稱為基本事件)的全體組成一個基本空間 (見概率)。隨機變量 是定義於 上的函數,即對每一基本事件
(見概率)。隨機變量 是定義於 上的函數,即對每一基本事件 ,有一數值
,有一數值 與之對應。以擲一顆骰子的隨機試驗為例,它的所有可能結果,共6個,分別記作
與之對應。以擲一顆骰子的隨機試驗為例,它的所有可能結果,共6個,分別記作 ,
,  ,
,  ,
,  ,
,  ,
,  ,這時,
,這時, ,而出現的點數這個隨機變量 ,就是 上的函數
,而出現的點數這個隨機變量 ,就是 上的函數 ,
, 。又如設
。又如設 是要進行抽查的
是要進行抽查的 個人的全體,那麼隨意抽查其中一人的身高和體重,就構成兩個隨機變量 和 ,它們分別是 上的函數:
個人的全體,那麼隨意抽查其中一人的身高和體重,就構成兩個隨機變量 和 ,它們分別是 上的函數: 「
「 的身高」,
的身高」, 「 的體重」,
「 的體重」, 。一般說來,一個隨機變量所取的值可以是離散的(如擲一顆骰子的點數隻取1到6的整數,電話台收到的呼叫次數隻取非負整數),也可以充滿一個數值區間,或整個實數軸(如液體中懸浮的微粒沿某一方向的位移)。
。一般說來,一個隨機變量所取的值可以是離散的(如擲一顆骰子的點數隻取1到6的整數,電話台收到的呼叫次數隻取非負整數),也可以充滿一個數值區間,或整個實數軸(如液體中懸浮的微粒沿某一方向的位移)。
在研究隨機變量的性質時,確定和計算它取某個數值或落入某個數值區間內的概率是特別重要的。因此,隨機變量取某個數值或落入某個數值區間這樣的基本事件的集合,應當屬於所考慮的事件域。根據這樣的直觀想法,利用概率論公理化的語言,取實數值的隨機變量的數學定義可確切地表述如下:概率空間 上的隨機變量 是定義於 上的實值可測函數,即對任意 , 為實數,且對任意實數
上的隨機變量 是定義於 上的實值可測函數,即對任意 , 為實數,且對任意實數 ,使
,使 的一切
的一切 組成的 的子集
組成的 的子集 是事件,也即是
是事件,也即是 中的元素。事件 常簡記作
中的元素。事件 常簡記作 ,並稱函數
,並稱函數 ,
, ,為 的分布函數。
設 , 是概率空間 上的兩個隨機變量,如果除去一個零概率事件外, 與
,為 的分布函數。
設 , 是概率空間 上的兩個隨機變量,如果除去一個零概率事件外, 與 相同,則稱
相同,則稱 以概率1成立,也記作
以概率1成立,也記作 或 ,α.s.(α.s.意即幾乎必然)。
或 ,α.s.(α.s.意即幾乎必然)。
有些隨機現象需要同時用多個隨機變量來描述。例如對地面目標射擊,彈着點的位置需要兩個坐標才能確定,因此研究它要同時考慮兩個隨機變量,一般稱同一概率空間 上的 個隨機變量構成的 維向量 為 維隨機向量。隨機變量可以看作一維隨機向量。稱 元
為 維隨機向量。隨機變量可以看作一維隨機向量。稱 元 的函數為 的(聯合)分布函數。又如果
的函數為 的(聯合)分布函數。又如果 為二維隨機向量,則稱
為二維隨機向量,則稱 為復隨機變量。
隨機變量的獨立性 獨立性是概率論所獨有的一個重要概念。設 是 個隨機變量,如果對任何 個實數 都有 即它們的聯合分布函數
為復隨機變量。
隨機變量的獨立性 獨立性是概率論所獨有的一個重要概念。設 是 個隨機變量,如果對任何 個實數 都有 即它們的聯合分布函數 等於它們各自的分布函數
等於它們各自的分布函數 的乘積。則稱 是獨立的。這一定義可以直接推廣到每一
的乘積。則稱 是獨立的。這一定義可以直接推廣到每一 ( )是隨機向量的情形。獨立性的直觀意義是: 中的任何一個取值的概率規律,並不隨其中的其他隨機變量取什麼值而改變。在實際問題中通常用它來表徵多個獨立操作的隨機試驗結果或多種有獨立來源的隨機因素的概率特性,因此它對於概率統計的應用是十分重要的。
( )是隨機向量的情形。獨立性的直觀意義是: 中的任何一個取值的概率規律,並不隨其中的其他隨機變量取什麼值而改變。在實際問題中通常用它來表徵多個獨立操作的隨機試驗結果或多種有獨立來源的隨機因素的概率特性,因此它對於概率統計的應用是十分重要的。
從隨機變量(或向量) 的獨立性還可以推出:設 是 取值的空間中的任意波萊爾集, 。設 是獨立的,則它們中的任意個都是獨立的。但逆之即使其中任何
是 取值的空間中的任意波萊爾集, 。設 是獨立的,則它們中的任意個都是獨立的。但逆之即使其中任何 個是獨立的,也不保證 是獨立的。又如果
個是獨立的,也不保證 是獨立的。又如果 ,是 個連續函數或初等函數(或更一般的波萊爾可測函數),則從 的獨立性可推出
,是 個連續函數或初等函數(或更一般的波萊爾可測函數),則從 的獨立性可推出 也獨立。如果隨機變量(隨機向量)序列
也獨立。如果隨機變量(隨機向量)序列 中任何有限個都獨立,則稱之為獨立隨機變量(隨機向量)序列。
關於隨機變量的矩、特徵函數、母函數及半不變量,分別見數學期望、方差、動差及概率分布。
中任何有限個都獨立,則稱之為獨立隨機變量(隨機向量)序列。
關於隨機變量的矩、特徵函數、母函數及半不變量,分別見數學期望、方差、動差及概率分布。















